
Funnel Analysis Using dbt + Snowflake+ Sigma
The modern data stack is essential for storing, transforming and visualizing data and enables an analytics engineer to model data into clean data sets that empower users throughout the company to answer their own questions. Three of the most widely used tools in this stack are Snowflake (for storing data in a cloud data warehouse), dbt (for transforming data) and Sigma (for visualizing data).
I had previously used dbt to rebuild the data stack from another project to allow for greater flexibility and transparency but I felt that I had only scratched the surface of its functionality. As a result, I was interested in deepening my understanding of dbt by building a more advanced project so I signed up for CoRise’s Analytics Engineering with dbt course. I was specifically drawn to the course due to its focus on mimicking the on-the-job realities that often face an analytics engineer such as transforming messy customer data in Snowflake and facilitating downstream exposures including my Sigma dashboard that visualizes how users move through a product funnel.
Model Layers and Macros
I had used staging, dimension and fact models in my previous dbt project but the CoRise Greenery project definitely sharpened my understanding about best practices for modeling data in a way that enables easy refactoring without needing to continually create new models to answer future questions. For example, the fact model for my product funnel (fct_product_funnel) references prior intermediate models (int_session_events_agg, int_sessions_with_event_type) which in turn reference the staging model for my event data (stg_postgres_events) and, in turn, the source data. As a result, I can easily modify these existing models or create new intermediate/fact models to answer future questions from stakeholders.
I did not use intermediate models in my previous dbt project but instead jumped directly from my staging models to fact models; in retrospect, I likely siloed some reusable business logic within my fact models that could have potentially been used elsewhere in my project so I definitely have a better understanding of the value of intermediate models and how to structure my model layers to maximize efficiency.
Similarly, I did not use macros in my previous dbt project but I now definitely appreciate their ability to simplify the code within a model! In this project, I used a macro to aggregate the number of event types per session within my int_session_events_agg model. As a result, the macro eliminated the need to manually loop over each event type which significantly simplified my code.





Testing and Packages
After completing this project, I now have a much deeper understanding of the possibilities for testing data within dbt. In my previous project, I used the generic tests (e.g. unique, not_null) that are built into dbt which was useful for verifying that user ids were unique and columns that should contain data actually do. However, these generic tests only had a relatively finite utility so I was excited to learn about the breadth of tests available through dbt packages created by the broader dbt community, particularly dbt_utils and dbt_expectations. In particular, the dbt_utils package was useful for asserting that a column’s values fell within a particular range using the accepted_range test while dbt_expectations was helpful for verifying that a column contained data with a specific timestamp format through expect_column_values_to_be_of_type.
Additionally, incorporating robust testing into the dbt deployment empowers an analytics engineering team to verify data quality with each scheduled run or be alerted via Slack in the event of a test failure which can then be quickly resolved!

Snapshots
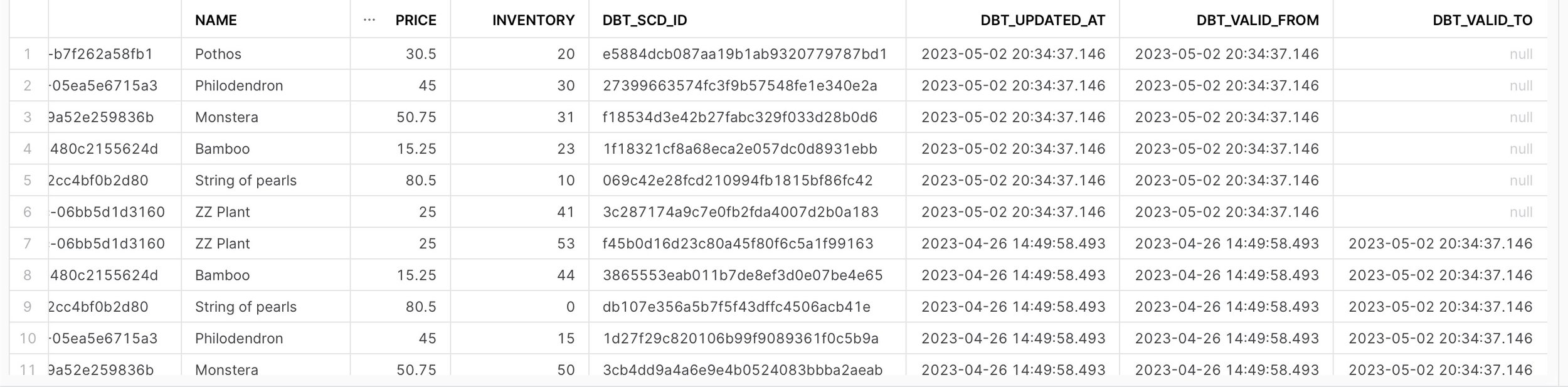
Snapshots are a powerful dbt feature for tracking how data changes over time which provided a great solution for tracking inventory changes over the course of this project. Without this functionality, I would only know what the inventory looked like at the time of my query as opposed to seeing how inventory has changed over time which is valuable information for any business. Specifically, I used the check strategy to create my snapshot which compares a list of columns between their current and historical values. As a result, if any columns have changed, dbt will invalidate the old record and create a new row in the snapshot with the current data. Snapshots also provide dbt_valid_from and dbt_valid_to columns which are particularly useful for understanding when inventory changes occurred for a particular product.

Artifacts, Deployment and Exposures
Maintaining both clarity and performance are essential as a dbt project and its DAG continue to grow over time. Luckily, dbt generates artifacts containing valuable metadata with each dbt invocation (e.g. run, test) that provide useful insights about the current state of the dbt project and what can be improved in the future to enhance efficiency. Specifically, I was interested in the run_results.json artifact, which indicates how efficiently my models and tests are performing over time, as well as the manifest.json artifact, which provides information about how my project is configured that would be important for understanding how different models, sources and exposures are interconnected as the project expands in size.
Similarly, when the dbt project is ready to be used to solve real business questions, it is important to deploy the project to production in order to automatically run, snapshot and test models on a given schedule. As a result, the analytics engineering team can routinely verify data quality and model freshness in order to proactively resolve any issues rather than learning about a problem only when a downstream dashboard stops working.
Models often have downstream dependencies such as dashboards that could potentially be affected by changes to a dbt model. As a result, exposures are a useful way to identify the most critical models and highlight the potential downstream effects of altering those models. For example, I created an exposure for my product funnel dashboard, indicated by the orange node in the DAG, which alerts team members that specific models are being used for downstream analysis within a Sigma workbook.
In my Sigma workbook, I focused on visualizing important product funnel data that would be most useful to a CPO and CEO. Specifically, I identified the number of unique sessions resulting in a page view, add-to-cart and checkout as well as resulting conversion rates between these stages. Additionally, company leaders would likely be interested in how the conversion rate varies per product so I visualized the overall conversion rate for each as well as the average session duration by session start hour to determine when the site receives the most traffic. As a result, this data could be used to promote specific products and send marketing emails during the most active hours to boost overall conversion.